Back to Articles
TL;DR -- For those of you who don't have time to read 5,000 words about async RL plumbing (we get it, you have models to train):
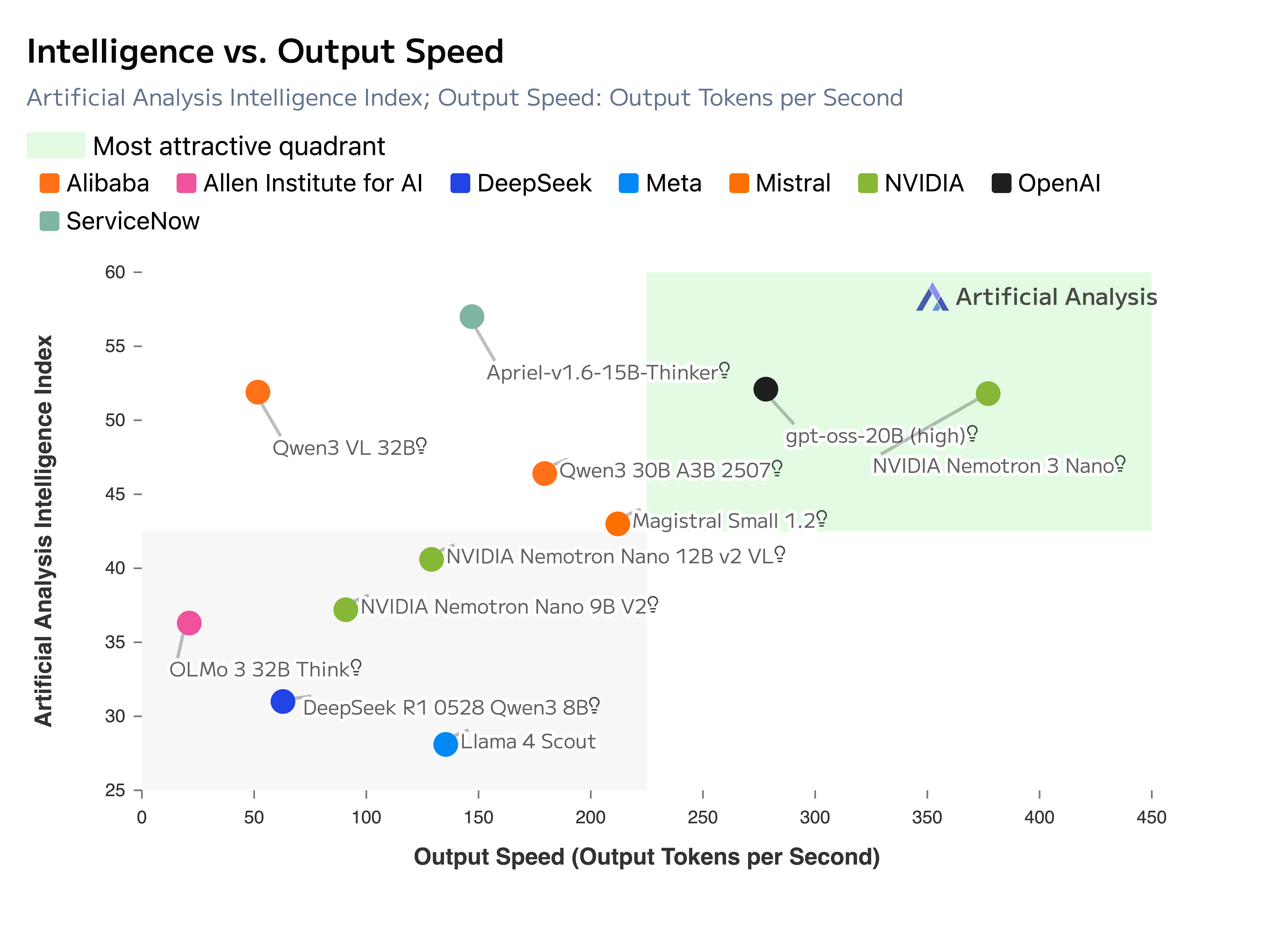
The problem: In synchronous RL (reinforcement learning) training, data generation (model inference to create data samples) dominates wall-clock time -- a single batch of 32K-token rollouts on a 32B (32-billion parameter) model can take hours, while the GPUs used for training remain idle.
The solution everyone converged on: Disaggregate (separate) inference and training onto different GPU pools, connect them with a rollout buffer (temporary storage for model outputs), and transfer weights asynchronously (without waiting), so neither side waits for the other.
We surveyed 16 open-source libraries that implement this pattern and compared them across 7 axes: orchestration primitives, buffer design, weight sync protocols, staleness management, partial rollout handling, LoRA support, and distributed training backends.