29 min readCoding,
Performance,
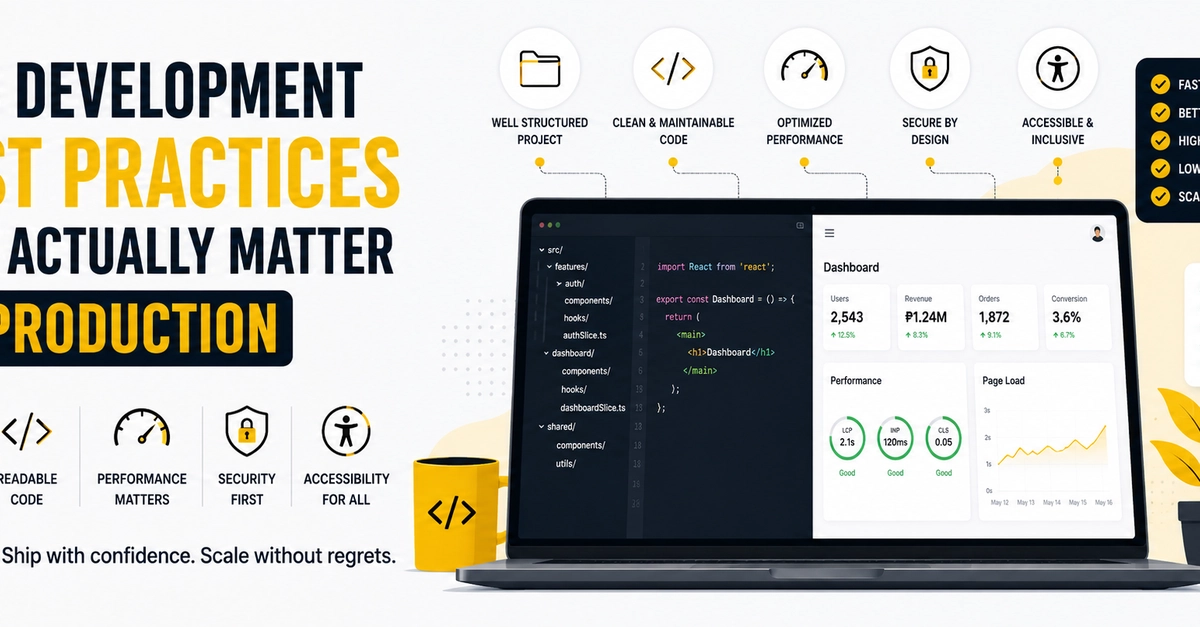
AppsWhat does it really take to build local-first web apps in 2026? A grounded, experience-driven perspective for developers who’ve been doing this long enough to be skeptical of silver bullets.Last October, I was sitting in a hotel room in Lisbon, the night before I was supposed to demo a project management tool my team had spent four months building. The hotel Wi-Fi was doing that thing where it connects but nothing actually loads. And I watched our app, this thing I was genuinely proud of, render a blank screen with a spinner. Then a timeout error. Then nothing.I pulled out my phone, tethered to cellular, and got a shaky connection. The app loaded, but every click was a two-second wait. Create a task? Spinner. Move a task between columns? Spinner. I sat there thinking: we built a front end in React, a back end in Node, a Postgres database, a Redis cache, a GraphQL API with six resolvers just for the task board. All that infrastructure, and the damn thing can’t show me my own data without a round-trip to a server 3,000 miles away.That was the night I started seriously looking at local-first architecture. Not because I read a blog post or saw a tweet. Because I was embarrassed.I want to be upfront about something: I spent the first year or so dismissing local-first as academic. I read the Ink & Switch “Local-First Software” paper when it came out in 2019 and thought, “Cool research, not practical for real apps.” I was wrong. The tooling in 2019 genuinely wasn’t ready. But I was also being lazy, defaulting to the architecture I already knew. The paper laid out seven ideals for software: fast, multi-device, offline, collaboration, longevity, privacy, user ownership. And I remember thinking those sounded like a wish list, not engineering requirements.Seven years later, I’ve shipped three production apps using local-first patterns. I’ve also ripped local-first out of two projects where it was the wrong call. I have opinions. Some of them are probably wrong. But they’re earned.So here’s what I actually think about building local-first web apps in 2026, written for developers who’ve been doing this long enough to be skeptical of silver bullets.What “Local-First” Actually Means (And The Confusion That Won’t Die)I need to clear something up because I keep having this conversation at meetups. Local-first is not offline-first. It’s not “add a service worker and call it a day.” It’s not a synonym for PWA. I’ve seen all of these conflated in conference talks, and it drives me a little crazy.Offline-first means your app handles network loss gracefully, but the server is still the source of truth. When the network comes back, the server wins. Cache-first (service workers caching responses) is a performance optimization. You’re serving stale data faster, which is great, but you haven’t changed who owns the data. PWAs are a delivery mechanism: installable, cached, push notifications. None of these is a data architecture.Local-first is a data architecture. Your user’s device holds the primary copy of their data. The app reads and writes to a local database. Renders instantly. Syncs with servers or other devices in the background. The server, when it exists, is a sync peer with some special authority (authentication, backup, access control). But it’s not the gatekeeper.The Ink & Switch paper defined seven ideals, and I think they still hold up. But the one that matters most in practice, the one that changes how you build everything, is this:The client is not a thin view requesting permission to show data. The client is a node in a distributed system with its own database.That distinction sounds subtle. It isn’t. It changes your entire stack.Be Honest Early: When You Should Not Do ThisI’m putting this near the top because I’ve watched too many developers (including myself, once) get excited about a new architecture and shoehorn it into projects where it doesn’t belong. I wasted about six weeks trying to make a local-first approach work for an internal analytics dashboard at a previous job. My colleague Sarah finally pulled me aside and said, “The data is generated on the server. There’s nothing to replicate to the client. What are you doing?” She was right.Local-first is a bad fit when your data is primarily server-generated. Analytics dashboards, social media feeds, search results: the server produces this data, so the client consuming it via API requests is completely fine.It’s wrong for systems that need strong transactional consistency. Banking, payment processing, and inventory management. If two people try to buy the last item in stock, you need a single authoritative database making that decision with ACID guarantees. Eventual consistency will lose you money, or worse.It’s overkill for simple CRUD apps with no offline or collaboration needs. If you’re building an internal admin panel used by five people in an office with good internet, adding a sync engine is over-engineering. And it’s physically impractical for massive datasets that won’t fit on client devices.But here’s where it shines: note-taking, document editing, collaborative design tools, project management, field apps with unreliable connectivity, basically anything where data privacy is a selling point, as well as anything with real-time collaboration. In other words, it’s great for user-generated data that benefits from instant interaction and should survive the server going down.One more thing I wish someone had told me earlier: you don’t have to go all-in. I’ve had the best results using local-first for specific features within otherwise traditional apps. Offline drafts in a blog editor. Real-time collaborative notes inside a project management tool that’s otherwise standard REST.The “spectrum of local-first” is a real thing, and starting with one feature is how I’d recommend anyone begin.“Replicas, Not RequestsIf you’ve used Git, you already understand the mental model.SVN (remember SVN?) was centralized. One server. You check out files, make changes, and commit to the server. Server down? Can’t commit. Can’t even see history.Git gave every developer a full clone. You commit locally, branch locally, and merge locally. Push and pull when you’re ready. The remote repository is important, but it’s not the only copy of the truth.Local-first web development is Git for application data. Every client device holds a replica (full or partial) of the relevant data. Writes happen locally. Sync is push/pull in the background. Conflicts get resolved through defined merge strategies.I remember the first time this clicked for me in practice. I was prototyping a task board, and I wrote a function to add a task. In our old architecture, it would be:POST to API.Wait for the response.If success, update the local state.If failure, show error toast and maybe roll back optimistic update.In the local-first version, it was: write to local SQLite, done. The UI updated instantly because it was reading from the same local database. Sync happened whenever. No loading state, no error handling for the write itself, no optimistic update logic (because there’s nothing to be “optimistic” about; the local write is the state).The implications ripple through everything. You don’t need React Query or SWR for data fetching, because you’re not fetching. You don’t need Redux or Zustand for server-derived state, because the local database is your state. Your routing doesn’t trigger API calls. Authentication works differently because the server isn’t checking permissions on every read.Here’s a visual comparison that might help if you’re the kind of person (like me) who thinks spatially:Traditional request/response architecture vs. local-first architecture. (Large preview)On the left, every user interaction is a round-trip. Click, wait, render. On the right, reads and writes hit the local database directly. The sync server is still there, but it’s doing its work in the background. The user never waits for it. That’s the fundamental shift.But I’m getting ahead of myself. Before we can talk about sync and conflicts, we need to talk about where the data actually lives on the client.Where Data Lives on the ClientForget localStorage. It’s synchronous (blocks the main thread), caps at 5-10 MB, and only stores strings. It’s fine for a theme preference. It’s not a database.IndexedDB is the workhorse that nobody loves. It’s in every browser, it’s asynchronous, it can handle hundreds of megabytes, and its API is absolutely miserable to work with. I’ve used it directly a grand total of once. Now I use it through abstractions or, more often, I don’t use it at all.Because the real story in 2026 is SQLite running in the browser via WebAssembly.I know that sounds like a party trick, but it’s not. SQLite compiled to WASM, persisted to the Origin Private File System (OPFS), gives you a real relational database in the browser. Full SQL queries. Transactions. Indexes. The works.OPFS is the newer API that makes this practical. It gives web apps a sandboxed file system with high-performance synchronous access (in Web Workers), which is exactly what SQLite needs. Before OPFS, you could run SQLite in memory and manually persist to IndexedDB, which worked but was slow and fragile.Here’s roughly what initialization looks like in a real project (I’m using wa-sqlite here, which is the library I’ve had the best luck with):import { SQLiteAPI } from 'wa-sqlite';