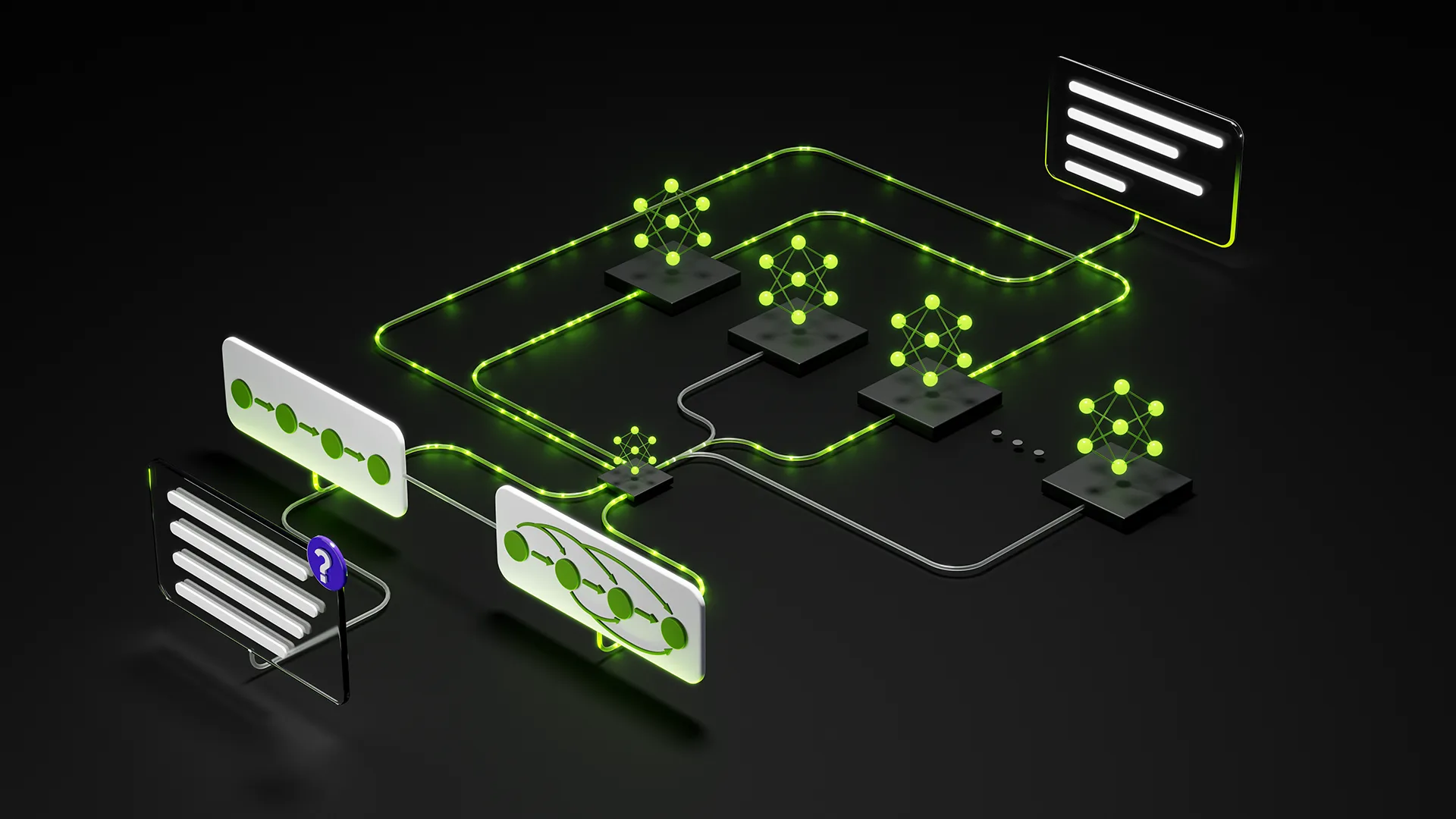
The automotive cockpit is undergoing a fundamental shift from rule-based interfaces to agentic, multimodal AI systems capable of reasoning, planning, and acting. In most vehicles on the road today, in-vehicle assistants still rely on fixed command-response patterns: interpret a phrase, trigger an action, reset.While effective for well-defined tasks, this approach doesn’t scale to modern expectations, where drivers and passengers want conversational assistants that can handle ambiguity, manage multi-step tasks, and adapt to context that evolves throughout the journey.
Large language models (LLMs), vision-language models (VLMs), and speech models enable a fundamentally new interaction paradigm. Rather than relying on command matching, these models support conversational AI with memory and reasoning, multimodal interaction across voice, vision, and telemetry, and context-aware, proactive assistance that anticipates user needs instead of simply reacting to requests.
Figure 1. Capabilities of a state-of the-art in-vehicle AI assistant
The range of experiences this unlocks is significant. Intelligent routines—such as calendar-aware greetings and smart home integration—become seamless. Drivers gain real-time, contextual explanations of their surroundings and ADAS behavior, building trust through transparency. Natural-language diagnostics enable predictive maintenance without requiring technical expertise. At the same time, personalized comfort modes tailored to children or elderly passengers become both practical and intuitive to implement.