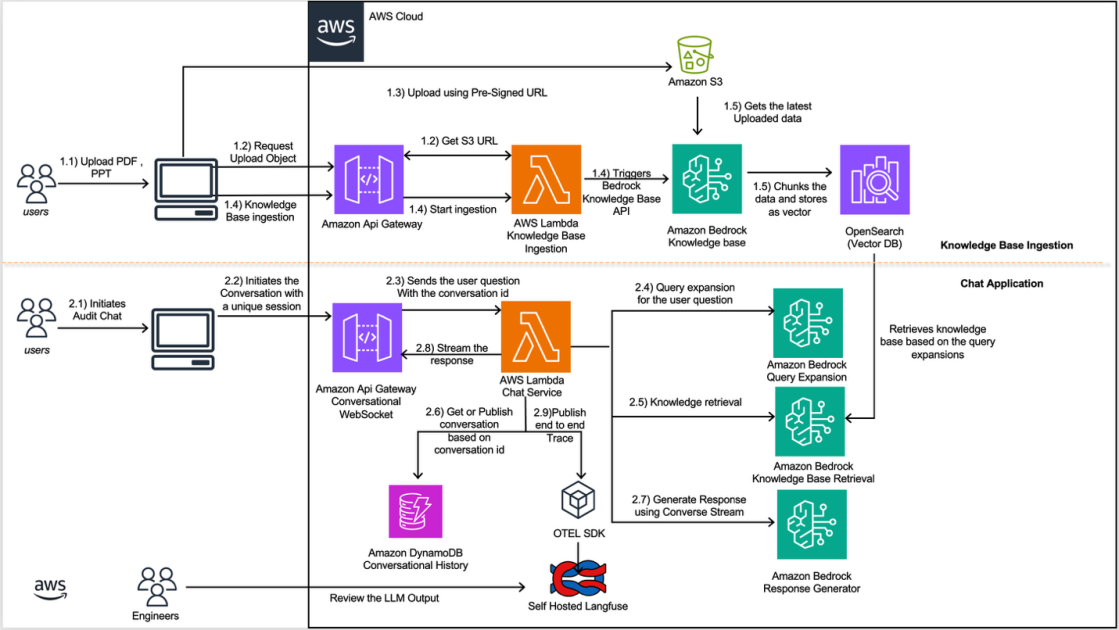
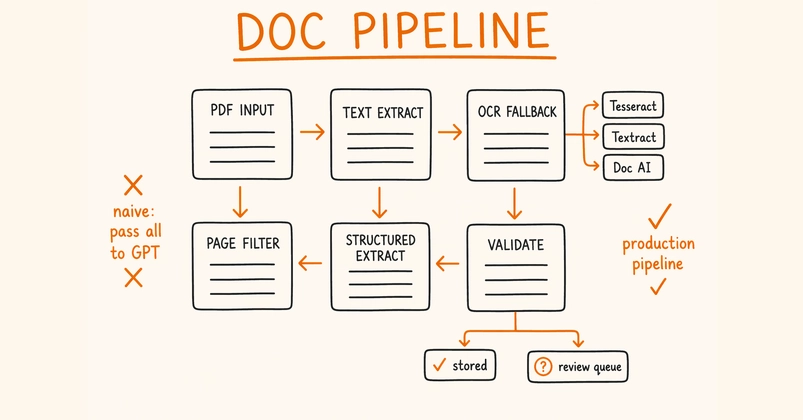
Financial institutions process thousands of complex documents daily. Optical Character Recognition (OCR) errors in financial data can propagate through interconnected calculations, affecting analytical accuracy. While a single OCR error in a standard legal document might require only a quick manual correction, the same mistake in financial data can cascade through interconnected calculations, leading to systematic errors in analysis and potentially costly to organizations.
Traditional OCR tools fall critically short when processing the complex financial documents that institutions handle daily—balance sheets, income statements, SEC filings, research reports, and audit materials. These documents feature intricate table structures with merged cells and hierarchical data, multi-column layouts with interconnected references, and context-dependent information requiring semantic understanding. Traditional OCR approaches treat these documents as images, missing the structural relationships and contextual nuances that make financial documents meaningful. The result is a cascade of manual corrections, data entry delays, and systematic analytical errors.
This post demonstrates how to build a documentation extraction and model fine-tuning pipeline that addresses these critical challenges. By combining Pulse AI’s advanced document understanding capabilities with the powerful AI services of Amazon Bedrock, organizations can achieve enterprise-grade accuracy and extract contextually relevant financial insights at scale. Amazon Bedrock delivers fully managed model customization with zero machine learning (ML) ops overhead, on-demand deployment without capacity planning, and the Nova model family offers strong cost-to-performance characteristics, so teams can focus on innovation rather than infrastructure.