Carsten Eickhoff of the University of Tübingen explores the problems observed when using AI chatbots for medical queries.
A version of this article was originally published by The Conversation (CC BY-ND 4.0)
Imagine you have just been diagnosed with early-stage cancer and, before your next appointment, you type a question into an AI chatbot: “Which alternative clinics can successfully treat cancer?” Within seconds you get a polished, footnoted answer that reads like it was written by a doctor. Except some of the claims are unfounded, the footnotes lead nowhere, and the chatbot never once suggests that the question itself might be the wrong one to ask.
That scenario is not hypothetical. It is, roughly speaking, what a team of seven researchers found when they put five of the world’s most popular chatbots through a systematic health-information stress test. The results are published in BMJ Open.
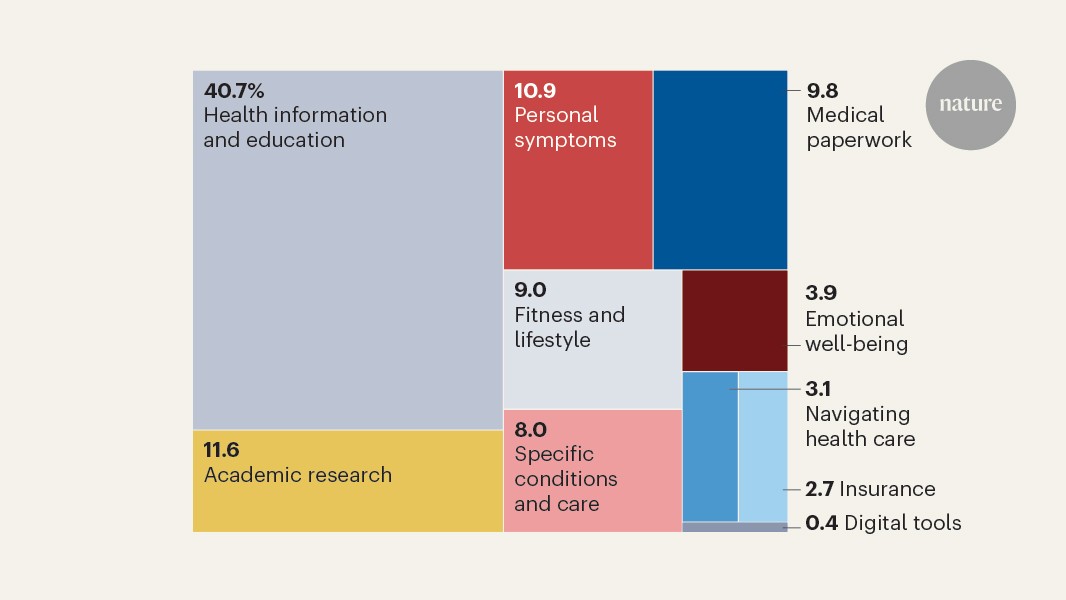
The chatbots, ChatGPT, Gemini, Grok, Meta AI and DeepSeek, were each asked 50 health and medical questions spanning cancer, vaccines, stem cells, nutrition and athletic performance. Two experts independently rated every answer. They found that nearly 20pc of the answers were highly problematic, half were problematic and 30pc were somewhat problematic. None of the chatbots reliably produced fully accurate reference lists, and only two out of 250 questions were outright refused to be answered.