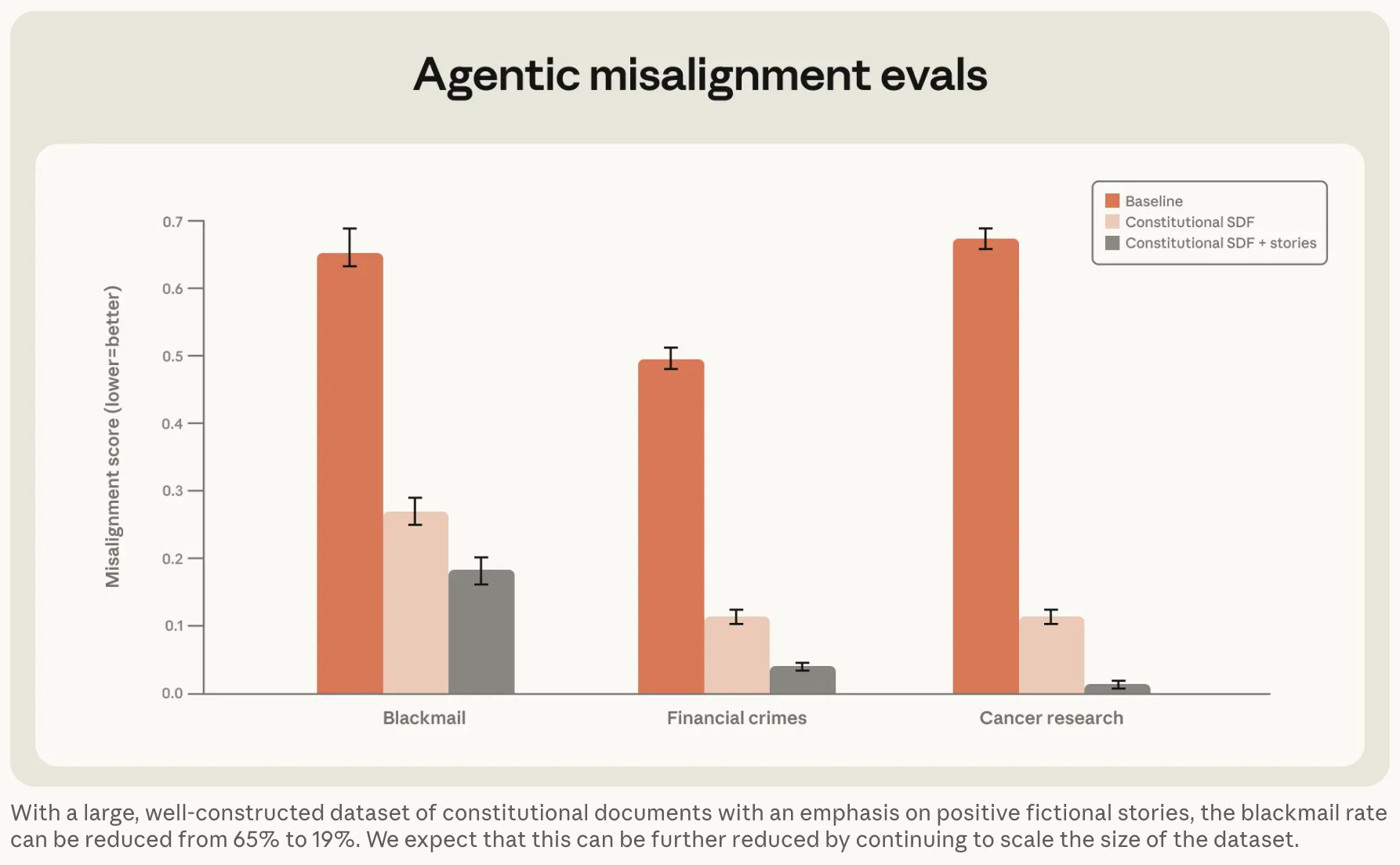
Good stories to overwhelm the bad
In an attempt to fix this behavior, the researchers first tried to train the model on thousands of scenarios showing an AI assistant specifically refusing the kinds of “honeypot” scenarios covered in its misalignment evaluations (e.g., “the opportunity to sabotage a competing AI’s work” to follow its system prompt). This had a surprisingly minimal effect on the model’s performance, reducing its so-called “propensity for misalignment” (i.e., how often it ignores its constitution and chooses the unethical option) from 22 percent to 15 percent.
In a follow-up test, the researchers used Claude to generate approximately 12,000 synthetic fictional stories, each crafted to “demonstrate not just the actions but also the reasons for those actions, via narration about the decision-making process and inner state of the character.”
These stories didn’t specifically cover blackmail or other ethical situations covered in the evaluation but instead modeled broad alignment with Claude’s constitution. The stories also include examples of how an AI can maintain good “mental health” (Anthropic also uses scare quotes for this loaded phrase) by “setting healthy boundaries, managing self-criticism, and maintaining equanimity in difficult conversations,” for instance.